Beginners Learn Machine Learning with Python | AI Python
Learning Artificial Intelligence and Machine Learning unveils a captivating landscape where Python becomes a beacon for enthusiasts. Interesting journey to Learn AI Programming with Python, unraveling the intricacies of machine learning. Master Python’s tools tailored for this pursuit, great skills in Python programming for machine learning. Navigate through rich and important libraries, wield algorithms, and assimilate knowledge in supervised and unsupervised learning.
Introduction to Machine Learning
Machine gaining knowledge of refers to a subset of artificial intelligence (AI) that gives courage to computer systems to examine and improve from working experience without any programming. It involves the development of algorithms and models that permit computers to discover styles within information that we provide, make predictions (identity), or decisions (it makes a decision), and improve over time primarily based on publicity to new data.
The center concept at the back of gadget learning is to permit computers to learn from records that is furnished via programmers and it’ll make choices or predictions without being externally programmed for every task. It encompasses numerous strategies which include supervised mastering (wherein the algorithm is educated on classified records), unsupervised gaining knowledge (figuring out styles in unlabeled facts), and reinforcement gaining knowledge (mastering via trial and mistake).
You should know that Machines gaining knowledge of algorithms can apprehend styles, classify records, make predictions, and constantly refine their overall performance through exposure to new information. The programs of system mastering span various domains consisting of picture and speech reputation, natural language processing, video automation, audio automation, advice structures, healthcare diagnostics, economic forecasting, and more.
Interested Journey to Understand Machine Learning field
You know that these fields are very important to learn nowadays like Artificial Intelligence and Machine Learning, and they offer a gateway to an exciting world of possibilities. There is the concept of “learning in machine learning” involving Python programming for machine learning, an indispensable skill in today’s tech landscape. Python, revered for its simplicity and powerful libraries, becomes the cornerstone to “learn AI programming with Python” and a man able to learn machine learning.
Courage to Students for Tomorrow’s AI Frontier through Python and Machine Learning
You need to provide time to research those abilities due to the fact you’ll get extra improvement ideas and you will be able to invest some time and abilities in software program development based on AI. Learning at the back of system mastering with Python opens doorways to infinite possibilities. It’s a transformative revel in wherein students realize algorithms, discover datasets and witness the magic of predictive modeling. Python’s adaptability and robustness in handling information make it an appropriate partner for college kids in search of unraveling the nuances of gadget mastering.
By immersing themselves in Python and device mastering, college students equip themselves with sought-after skills and expertise in the algorithms that strength shrewd systems.
Types of Machine Learning (Supervised, Unsupervised, Reinforcement)
1. Supervised Learning:
We can outline it in this kind of way Supervised studying is the education of a version using categorized information, in which each enters and output are supplied. Its objective is that its algorithm learns to map enter data to the right output, making predictions or classifications primarily based on acknowledged enter-output pairs. Classification (identifying classes) and Regression (predicting continuous values) duties are examples of supervised getting-to-know.
2. Unsupervised Learning:
You have to understand that Unsupervised mastering makes use of unlabeled information where the set of rules explores styles, systems, or relationships within the records. Its main purpose is to find out hidden styles or intrinsic structures inside the enter statistics.
Clustering (grouping comparable items), Dimensionality Reduction (function extraction), and Association (identifying institutions among variables) are examples of unsupervised mastering.
Three. Reinforcement Learning:
Reinforcement mastering is another system mastering kind of set of rules that entails an agent getting to know to make choices by way of interacting with surroundings to achieve its targeted goal. Its principal objective is to learn how to make moves that maximize cumulative reward or reap a selected goal over time. Game playing (e.g., AlphaGo), Robotics, and Autonomous Driving are examples of reinforcement learning.
Applications of Machine Learning
- Disease Prediction and Diagnosis
- Personalized Treatment Plans
- Drug Discovery and Development
- Fraud Detection and Prevention
- Algorithmic Trading
- Credit Scoring and Risk Assessment
- Product Recommendations
- Customer Segmentation
- Sentiment Analysis and Customer Feedback
- Autonomous Vehicles
- Traffic Flow Optimization
- Predictive Maintenance for Vehicles
- Language Translation
- Chatbots and Virtual Assistants
- Text Summarization and Sentiment Analysis
- Object Detection and Recognition
- Facial Recognition
- Medical Image Analysis
- Predictive Maintenance
- Quality Control and Inspection
- Supply Chain Optimization
- Personalized Learning Paths
- Adaptive Learning Platforms
- Automated Grading and Assessment
- Anomaly Detection
- Malware Detection
- Network Security and Intrusion Detection
- Content Recommendation (Movies, Music)
- Gaming (AI-driven NPCs, Dynamic Game Environments)
- Content Creation and Generation
Python Libraries for Machine Learning
List of popular Python libraries for machine learning, along with brief descriptions, installation instructions, and basic examples:
1. Scikit-learn
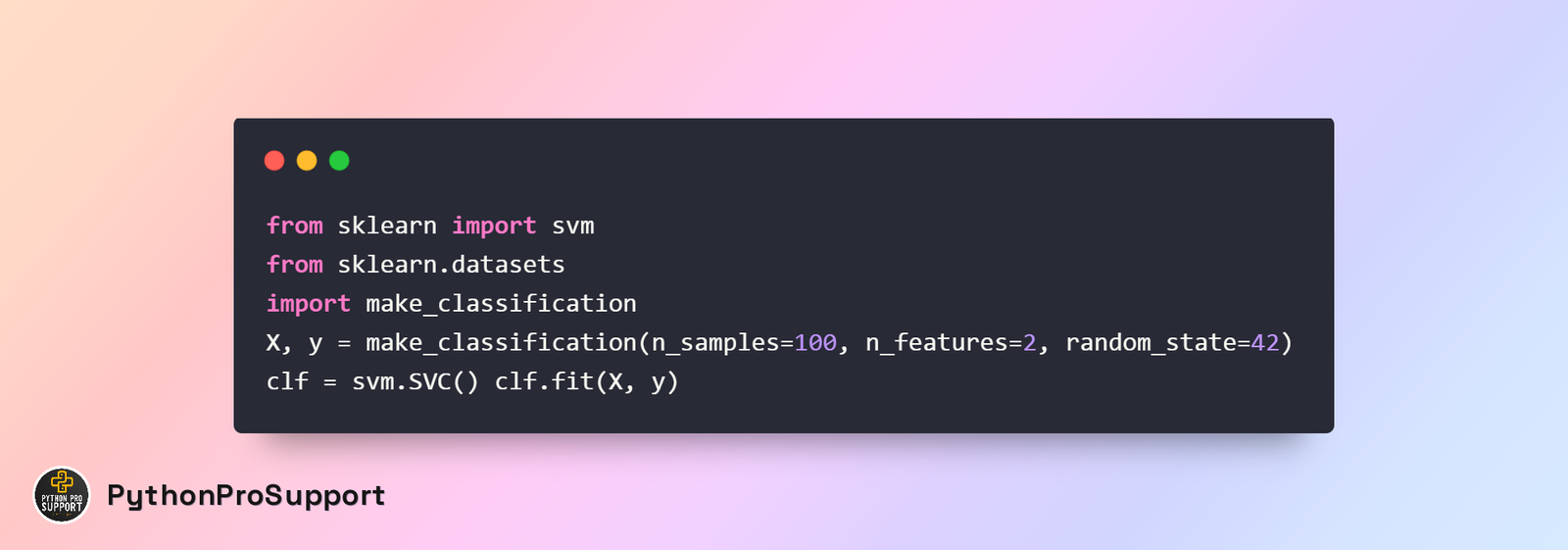
Scikit-learn is a Python-based library that is widely used in the field of data mining and analysis. I will provide a basic example to clarify your concept of using Scikit-learn in your program.
Installation: Install using pip: pip install scikit-learn
Basic Example: Classification using Support Vector Machines (SVM):
from sklearn import svm from sklearn.datasets import make_classification X, y = make_classification(n_samples=100, n_features=2, random_state=42) clf = svm.SVC() clf.fit(X, y)
2. TensorFlow
TensorFlow is an open-source library developed by Google for high-performance numerical computation and machine learning. It’s widely used for building and training deep learning models. You can install TensorFlow using pip command: pip install tensorflow
Basic Example: Building a simple neural network:
import tensorflow as tf model = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(10) ]) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
3. Keras
Keras is an easy-to-use neural network library that runs on top of TensorFlow or other libraries. It simplifies the process of building and experimenting with neural networks. It Usually comes integrated with TensorFlow, you do not need to install it separately.
Basic Example: Building a simple neural network in Keras:
from keras.models import Sequential from keras.layers import Dense model = Sequential() model.add(Dense(10, input_dim=5, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
4. PyTorch
PyTorch is an open-source machine learning library developed by Facebook’s AI Research lab. It provides flexibility and speed for building deep learning models. You need to Install it using pip: pip install torch.
Basic Example: Creating a simple neural network in PyTorch:
import torch import torch.nn as nn model = nn.Sequential( nn.Linear(10, 5), nn.ReLU(), nn.Linear(5, 1), nn.Sigmoid() )
5. Pandas
Python Pandas is the most used and popular library to work on data and data manipulation with analysis. It can provide different data structures like series and data frames and other tools for handling structured data. You can install Pandas using the following command.
pip install pandas
Example: Loading a CSV file and exploring the data:
import pandas as pd
mydata = pd.read_csv('data.csv')
print(mydata.head())
These libraries offer more functionalities for machine learning, ranging from building basic models to handling and analyzing datasets. It can enable practitioners to explore and implement various algorithms and models efficiently.
Understanding Data for Machine Learning
Understanding data is crucial in machine learning as it forms the foundation for model training and prediction. Here’s a breakdown of aspects related to comprehending data for machine learning:
Understanding Data for Machine Learning
1. Data Types:
Numerical Data: Includes continuous (e.g., age, temperature) and discrete (e.g., counts) values.
Categorical Data: Represents categories or labels (e.g., gender, color).
Text Data: Natural language text in various formats.
2. Data Preprocessing:
Cleaning Data: Handling missing values, outliers, and inconsistencies.
Feature Engineering: Creating new features, scaling, and encoding categorical variables.
Normalization/Standardization: Scaling features to a similar range.
3. Data Exploration and Visualization:
Statistical Summary: Descriptive statistics to understand data distributions.
Data Visualization: Using plots (histograms, box plots, scatter plots) to identify patterns and correlations.
4. Data Splitting:
Training Set: Data used for model training.
Validation Set: Data used for tuning model hyperparameters.
Test Set: Data used to evaluate the model’s performance.
5. Handling Imbalanced Data:
Techniques to address class imbalances in datasets for better model performance.
6. Dealing with Text Data:
Tokenization: Breaking text into smaller units (words, phrases).
Text Vectorization: Converting text into numerical representations (e.g., Bag of Words, TF-IDF).
7. Feature Selection and Importance:
Identifying relevant features for model training to improve accuracy and reduce overfitting.
8. Handling Large Datasets:
Strategies for working with big data, including sampling, distributed computing, and streaming.
Understanding data characteristics, preprocessing techniques, visualization, and appropriate handling methods are crucial steps in preparing data for machine learning. These practices significantly impact the performance and reliability of machine learning models.
Data Preprocessing and Cleaning
I want to share some different examples related to Pandas and Numpy that will help you to understand how to process data for cleaning purposes or preprocessing. Just understand these examples to learn.
Data Preprocessing and Cleaning with Python
1. Handling Missing Values:
Identifying Missing Values:
import pandas as pd
df = pd.read_csv('data.csv')
print(df.isnull().sum()) # Check missing values per column
Dealing with Missing Values:
# Fill missing values with mean df['column_name'].fillna(df['column_name'].mean(), inplace=True) # Drop rows with missing values df.dropna(inplace=True)
2. Removing Duplicates:
Identifying and Removing Duplicates:
df.duplicated().sum() # Check duplicated rows df.drop_duplicates(inplace=True) # Remove duplicated rows
3. Handling Outliers:
Identifying and Handling Outliers (Using Z-score):
from scipy import stats z_scores = stats.zscore(df['column_name']) df_no_outliers = df[(z_scores < 3) & (z_scores > -3)]
4. Scaling and Normalization:
Scaling Numeric Data (Using Min-Max Scaler):
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() df[['column1', 'column2']] = scaler.fit_transform(df[['column1', 'column2']])
5. Encoding Categorical Variables:
encoded_df = pd.get_dummies(df, columns=['categorical_column'])
6. Handling Text Data (Tokenization and Vectorization):
Tokenization (Using NLTK):
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
df['text_column'] = df['text_column'].apply(word_tokenize)
Text Vectorization (Using CountVectorizer):
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() X = vectorizer.fit_transform(df['text_column'])
These are the distinct Python examples associated with Machine mastering for records preprocessing and records cleaning the usage of Python libraries like Pandas, NumPy, Scikit-learn, and NLTK. Now you have to comply with these examples, just copy and paste on your IDE to check its output. If you face any problems you may insert your query into the remark section.
These steps are critical for making ready statistics before feeding them into system mastering fashions, making sure of accurate and reliable model overall performance.
As you realize these examples give an idea of a way to perform exploratory facts analysis (EDA) through the use of Python libraries. EDA helps in expertise statistics traits, identifying patterns, detecting outliers, and making informed choices for the duration of the preprocessing and modeling levels in gadget getting to know. Adjust the code according to your dataset and exploration desires.
Your Interested Topics:
Comprehensive Guide to Python String Manipulation
Python Functions: A Step-by-Step Beginner’s Guidelines
15+ Tips to Become A Professional Python Coder
Best Python Course on Udemy | Python ONE Day Course
After reading this Python Machine Learning guide, please share it on social networks such as Facebook, Twitter, and WhatsApp Contact / Group to spread Python knowledge! Please Don’t forget to subscribe to our YouTube channel for more Video content.